Deep Learning Accelerates Product Development

Tyan is one of several computer vendors with new systems using the latest NVIDIA GPU technology, designed for DL and other computationally intensive applications. Pictured is the Tyan Thunder HX FA77B7119. Image courtesy of Tyan.


Latest News
May 1, 2018
Recent advances in computer science have made it possible for computers to work more like the human brain than a high-speed mechanical calculator. But for a generation, most of the research made little practical progress for two very basic reasons: limited knowledge of how the human brain works, and the computing power needed to mimic human thinking processes was not widely available. Even with these limitations, progress has been made over the years in machine learning (ML), a branch of artificial intelligence (AI) that focuses on the application of pattern recognition to automate processes.
The 1990s saw an increase in machine learning research, and practical applications emerged. The U.S. Postal Service adopted ML handwriting recognition in 1999, taking advantage of its access to millions of handwriting samples. ML has since become an essential part of factory automation as well as various products where visual recognition can improve automation, such as in food processing, security systems and image recognition (think Facebook or some smartphone apps).
 Tyan is one of several computer vendors with new systems using the latest NVIDIA GPU technology, designed for DL and other computationally intensive applications. Pictured is the Tyan Thunder HX FA77B7119. Image courtesy of Tyan.
Tyan is one of several computer vendors with new systems using the latest NVIDIA GPU technology, designed for DL and other computationally intensive applications. Pictured is the Tyan Thunder HX FA77B7119. Image courtesy of Tyan.In recent years, a new method of ML has emerged: deep learning (DL). It uses neural networks (from AI research) and vast databases—neither of which were practical for commercial use until recently. DL uses neural net algorithms to train itself to understand a topic, seeking connections in the characteristics of a given data set. The DL algorithm creates multiple layers of characteristics, and uses the representations with multiple levels of abstraction.
A deep learning system does not need to be trained to recognize every example of a concept, as is the case with ML. Instead, DL learns from experience, seeking hidden patterns and organizing its findings as a hierarchy of layers from simple to complex. Researchers says DL more closely mimics the human brain than previous ML techniques.
Sample size is another key difference between ML and DL. Consider an example of sorting fasteners. Machine learning algorithms do their best operating with a small sample of data so it can continually ask: “Does this fastener match my data?” DL algorithms are first taught as much as can be provided about fasteners, building up knowledge that allows it to then ask: “How does this fit into what I know about fasteners?”
Smart manufacturing uses the advancements of DL to improve system performance and deepen automated decision-making. DL provides the advanced analytics required to process vast manufacturing data sets.
The widespread deployment of sensors and embedded computing defines what we now call the internet of things. But the deployment of smart hardware into parts and machines means there is an ever-increasing need for analytical tools to process all this real-time data and improve system performance. Thus the need for DL as an engineering tool in product development.
Six Steps to Building a Deep Learning System
The tools are now available to build custom DL systems, with software from vendors like MathWorks or Microsoft, from hardware vendors like NVIDIA and from process experts like Jonathan Hurlock, Ph.D., who consults for companies looking to exploit DL.
Hurlock says there are six steps in developing a DL system, independent of the specific tools in use. The six steps are as follows:
- Understanding the requirements. The first step is setting realistic goals, based on project requirements. “It is very important to understand the behavior we want to influence or allow,” says Hurlock. An example would be to increase successful recognition of misshapen parts by 8%.
- Research appropriate models and algorithms. Most DL projects start with one of several standard data models and algorithms that have been developed over the years. By breaking the larger problem down into several smaller problems, Hurlock says it becomes easier to match the right models and algorithms to each task.
- Obtain data and understand the data sources. DL is a process of working through data to discern relationships and common elements. Hurlock says this process happens in two ways: supervised learning and unsupervised learning. Supervised is based on learning from a set of existing labeled data—such as “these are good fasteners; these are bad fasteners.” Unsupervised is when the algorithm finds patterns where no labeled data exists.
- Feature generation and dimensionality reduction. Feature generation is an intermediate step that is sometimes used to bridge the gap between supervised and unsupervised DL preparation. An example would be breaking down signals from a sensor into categories and adding priorities to some categories. Dimensionality reduction is used to narrow the number of features that lead toward the solution, such as eliminating fasteners outside of a certain range of sizes.
- Train the model. A DL algorithm creates a model by finding patterns in the data and building a set of correlations to the target. The engineering goal in this step is to help the algorithm improve on the model by adjusting the data set until it reaches the requirements established in step 1.
- Evaluate the model. This is the step where you test the DL algorithm for predictive accuracy. Hurlock says this can be an iterative process, with several adjustments to the model, to feature inputs, or by providing more data. You might also come to the conclusion that the time and cost of this particular DL scenario does not offer enough ROI or cannot hit the requirements.
Deep Learning at MathWorks
Engineering software company MathWorks has been exploring the machine learning space since 1991, says Bruce Tannenbaum, MathWorks senior product marketing manager.
“We were doing machine learning before it was a big deal,” he says.
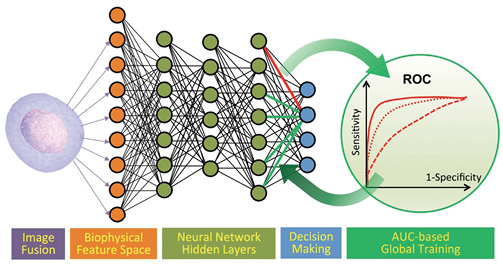 UCLA researchers used MathWorks Deep Learning tools to create a new diagnostic product for examining cancer cells that gives superior results over existing methods. The researchers say modeling the system with DL saved months of experimental time. The cancer cell neural net model was then repurposed for algal cell classification, by providing new data to the algorithm. Image courtesy of MathWorks.
UCLA researchers used MathWorks Deep Learning tools to create a new diagnostic product for examining cancer cells that gives superior results over existing methods. The researchers say modeling the system with DL saved months of experimental time. The cancer cell neural net model was then repurposed for algal cell classification, by providing new data to the algorithm. Image courtesy of MathWorks.Today it offers deep learning tools on both the MATLAB and Simulink product platforms; most engineering teams exploring DL with MathWorks tools are on the MATLAB platform.
MATLAB’s DL tools focus on feature extraction. Tannenbaum uses the example of how to get a computer to “see” a dog in an image. In ML you show the algorithm 1,000 images of dogs, then it uses that data comparatively. In DL, the algorithm studies 100,000 (or many more) photos of dogs to build a working model of “dogness.”
“What makes a photo of a dog a dog to the algorithm?” Tannenbaum asks. “Edges. Shapes. It is a process of detection and extraction,” in which the algorithm painstakingly, layer by layer, assembles a model that becomes the working definition.
The training time is filled with back propagation, feedback, testing and optimization. Tannenbaum says it can take days for the algorithm to arrive at a model.
As mentioned already, DL projects generally start with an existing neural net. The one most often used in MATLAB projects is called AlexNet, which was originally used for facial recognition but can be adapted to a variety of purposes. One MATLAB user worked with AlexNet to examine surface features above a mining tunnel drilling project. The retrained AlexNet was able to predict subsurface geological features well enough for field deployment. The model was able to determine when it would be necessary to call in a high-priced geologist and when the drillers could proceed without outside advice.
Reusing existing neural net models is common in DL projects, Tannenbaum says. A model might have 20 layers of understanding, with the first 10 or so the original AlexNet and the next 10 new layers of understanding created by the algorithm for the new project.
Image recognition and voice recognition are the two most common product-based applications for DL in product development today. DL has advanced the art of image recognition beyond simple tasks (identifying a screw) to finding cracks, identifying mistakes in a product, or recognizing the signs of a process failure as it happens. For voice (or sound) recognition, new algorithms have been developed that turn the sequential waveform of a sound into a spectrogram for faster analysis and classification.
Parallel Processing Breakthrough
DL is computationally intensive. MathWorks’ Tannenbaum says it is only in the last few years that engineering workstations have become powerful enough. The two most recent generations of NVIDIA GPUs offer enough power and can work with both Intel and AMD workstation or server CPUs.
At the NVIDIA GPU Technology Conference in March 2018, NVIDIA announced a series of performance advancements, which it claims will boost DL performance by 10x, compared with what the company offered only six months earlier. Specific improvements include a memory boost to the Tesla V100; a new GPU interconnect fabric called NVIDIA NVSwitch, which enables up to 16 Tesla V100 units to simultaneously communicate; and DGX-2, a new GPU-based server that delivers two petaflops of computational power. NVIDIA claims the DGX-2 “has the deep learning processing power of 300 servers occupying 15 racks of datacenter space, while being 60x smaller and 18x more power efficient.”
 A new DL-powered image synthesis technique from NVIDIA makes it possible to change the look of a street simply by changing the semantic label. San Francisco becomes Barcelona or another city. Although gaming is an obvious use for such a technology, it also can be applied to training autonomous vehicles. Image courtesy of NVIDIA.
A new DL-powered image synthesis technique from NVIDIA makes it possible to change the look of a street simply by changing the semantic label. San Francisco becomes Barcelona or another city. Although gaming is an obvious use for such a technology, it also can be applied to training autonomous vehicles. Image courtesy of NVIDIA.But How Hard is it?
This DL stuff sounds complicated, but for product development, most of the difficulty is under the hood. Tannenbaum says a typical engineer can learn the basics of DL in a day. MathWorks offers a variety of training videos, ebooks and other supportive materials. One three-minute MathWorks video shows how to create a basic DL routine with 11 lines of code.
Subscribe to our FREE magazine, FREE email newsletters or both!
Latest News
About the Author
Randall S. Newton is principal analyst at Consilia Vektor, covering engineering technology. He has been part of the computer graphics industry in a variety of roles since 1985.
Follow DE

