
Fig. 3: Lumiata uses machine learning-powered analytics, trained on more than 175 million patient-record years, to predict the risk of disease of individuals and populations. Here the software applied knowledge graph technology to create this visualization of upstream and downstream relationships with asthma. Image courtesy of Lumiata.


Latest News
July 1, 2017
As machine learning makes its way into more applications—leveraging everything from sensor data to consumer information repositories—pressure for hardware and software engineers to familiarize themselves with the technology grows. Because this type of control algorithm differs in key ways from those based on traditional logic, the learning curve may be steeper for some designers. Nevertheless, it’s time for all engineers to understand how this technology changes the design process and what tools and practices help with its implementation.
Devil is in the Differences
One of the best ways to understand machine learning is to consider how it differs from conventional control mechanisms. Traditional programming uses Boolean logic’s true and false rules to define a program’s behavior, building the application via a series of defined steps, where the rules making up the program ensure what action happens next.
Machine learning takes a different approach, built on inductive reasoning. Here, the system begins with a data set (the larger, the better), looks for patterns and then formulates a general theory (Fig. 1). This approach embodies a “learning” process that synthesizes general knowledge from large sets of information and inductively infers predictions that enable decisions.
 Fig. 1: Machine learning sifts through large data sets, looking for patterns and insights that human analysis could not identify. Derived from a medical knowledge graph developed by Lumiata, this visualization shows interrelationships between diagnoses. Image courtesy of Lumiata.
Fig. 1: Machine learning sifts through large data sets, looking for patterns and insights that human analysis could not identify. Derived from a medical knowledge graph developed by Lumiata, this visualization shows interrelationships between diagnoses. Image courtesy of Lumiata.Although Boolean logic-based programs are well suited for black-and-white type problems, machine-learning systems are tailor-made for more complex applications, such as image or speech recognition. Leveraging this strength, machine learning-enabled products grow “smarter” over time, automatically adapting decision-making rules using insights gleaned from “experience,” and making predictions based on patterns and properties “learned” from training data (Fig. 2).
 Fig. 2: Voice-controlled devices require the user’s voice to be captured and processed before they can deliver an appropriate response. Empowered by advanced voice microprocessors, Knowles “smart microphones” leverage the latest generation of machine learning algorithms to accurately recognize user-trained keywords. Image courtesy of Knowles Corp.
Fig. 2: Voice-controlled devices require the user’s voice to be captured and processed before they can deliver an appropriate response. Empowered by advanced voice microprocessors, Knowles “smart microphones” leverage the latest generation of machine learning algorithms to accurately recognize user-trained keywords. Image courtesy of Knowles Corp.Building a Machine Learning Application
Moving from this big-picture view of machine learning to the nuts and bolts of developing an application, it’s important to recognize the size of the undertaking. You are working with significant amounts of data, and it’s imperative that you understand its various features. By optimizing the data, you improve the application’s predictability.
Building one of these applications is an iterative process, consisting of a sequence of steps that begins with defining the problem that the machine learning must address, regarding what is observed and what the model must predict.
The next step involves collecting and preparing the data. The more data you have to train the algorithm, the more accurate it will be (Fig. 3). If you make the mistake of under-sampling at this point, you will reduce your chances of success.
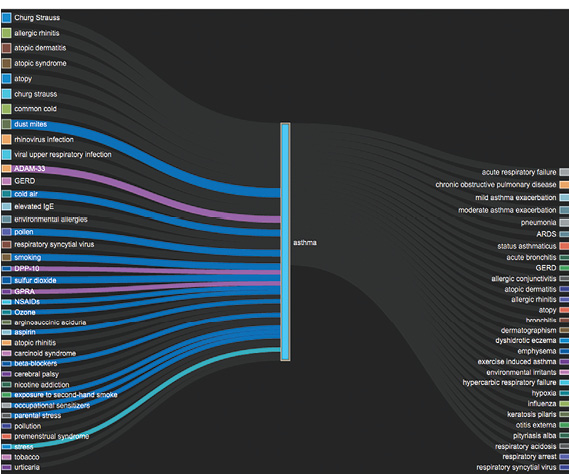 Fig. 3: Lumiata uses machine learning-powered analytics, trained on more than 175 million patient-record years, to predict the risk of disease of individuals and populations. Here the software applied knowledge graph technology to create this visualization of upstream and downstream relationships with asthma. Image courtesy of Lumiata.
Fig. 3: Lumiata uses machine learning-powered analytics, trained on more than 175 million patient-record years, to predict the risk of disease of individuals and populations. Here the software applied knowledge graph technology to create this visualization of upstream and downstream relationships with asthma. Image courtesy of Lumiata.In addition to providing the right amount of data, you must ensure that the data is suitable for training the learning algorithms. Often, input and output data must be properly prepared to enable the algorithm to train a predictive model. For example, the training data must contain the answer the prediction process seeks. This is called the target. Machine learning models are only as good as the data you provide. Adequate data collection and preparation are a must for building predictive models.
Different Types of Learning
Although design engineers rely on these established processes for building machine learning applications, it’s important to remember that machine learning is not a monolithic control technology. Designers have a choice between supervised and unsupervised algorithms. Each targets disparate types of applications, but both predict outcomes based on data.
Today, the most familiar machine learning applications use supervised learning. In this approach, the designer provides both example inputs and outputs to train the system. The designer also specifies the correlations to be found and asks the system to substantiate the correlations. One of the ways in which supervised algorithms are unique is that the output is already known.
A good example of this type of machine learning is a speech-recognition system. In the case of a speaker-independent system, the developer draws on a large vocabulary of words, training the system using sub-word models. After sufficient training, the system can recognize specific words.
Supervised learning models offer important advantages, but also has limitations. Chief among these is the inability to deal with new information. For instance, if a vision system has been trained with categories for cars and trucks, and it is presented with a bicycle, it incorrectly tries to place the bicycle in one of the two existing categories.
Examples of supervised learning applications include pattern recognition, spam detection and speech recognition. Perhaps the most common examples are the recommendation systems used by Netflix, Amazon and Google.
Unsupervised machine learning, on the other hand, represents a far more complex process. As a result, the market has not seen adoption on the same scale as supervised technology.
Unsupervised learning discovers patterns in data sets without being told to look for particular correlations. Engineers use these systems to find hidden structures in unlabeled data and to model the underlying structure or distribution of a data set. Developers often adopt this approach to discover patterns in data sets too complex for humans to work with. Examples of unsupervised learning applications include sequence and pattern mining and computer-vision object recognition.
This flavor of machine learning has generated a lot of excitement because industry watchers see it pointing to future applications of artificial intelligence where computers teach themselves rather than rely on people to develop them.
Picking the Right Application
Although machine learning enables a lot of compelling applications, some functions simply don’t need the level of “intelligence” that the technology offers. For instance, you don’t need machine learning if you can identify a target value using Boolean logic.
Design engineers should reserve machine learning for tasks that they cannot adequately solve with simple, rule-based programming. When rules depend on a large number of factors or must be tuned very finely, machine learning is the answer. Similarly, designers should choose machine learning when the scale of the problem moves beyond the ability of humans. For example, if you have so many patterns to recognize that the task becomes tedious, then machine learning-enabled systems work best.
The Importance of Data
When machine learning is appropriate, incorporating the technology into a design requires engineers to alter the way that they conceptualize and develop products and services. As a result, designers must come to terms with a raft of unique issues. Many of these revolve around data—what type of data is involved, how it is collected and whether it is compatible with the system’s architecture.
“The biggest and most important difference in the [machine learning] design process is data collection,” says Mike Kasparian, chief technology officer and cofounder of Atlas Wearables. “It involves developing or selecting a system for data collection before implementing and iterating on the machine learning algorithm.”
Designers must also select an architecture that best suits the characteristics of the data. Architecture in this context refers to the type of learning model applied. These range from probabilistic and graphical models to deep learning architectures. In addition, variations in model architectures—such as recurrent neural networks and convolutional neural networks—complicate the selection process.
Each of these architectures has its own strengths and weaknesses, depending on the type of input, characteristics of the input data and the desired output to be learned. “This is where experience and knowledge of the tradeoffs come into play,” says Ash Damle, CEO of Lumiata. “Some dimensions to consider include time to train, interpretability and flexibility of output.”
Above all, a design team must have a deep understanding of data science and the architecture options. Otherwise, incorporating machine learning into any system will be difficult.
Other Hurdles
Even well-targeted applications of machine learning run into challenges. Many of these obstacles involve tradeoffs that must be made between optimizing performance and meeting application constraints. “There are challenges around selecting optimal hardware to support the algorithm, with the design tradeoff that a possibly more accurate algorithm would consume more power and thus reduce battery life,” says Kasparian. “In our case, where we may be implementing the algorithm on a low-power MCU in a constrained environment, one may need more RAM to store classification models or hyperparameters, or a CPU optimized for single-cycle multiply accumulates (Fig. 4).”
 Fig. 4: Machine learning offers an excellent way of implementing compelling services in wearable devices, using personal and sensor data to train algorithms. To take advantage of the technology, however, designers must balance performance with space and power constraints. Atlas Wearables’ Wristband fitness tracker offers a good example of the elements that come into play in the tradeoff process. Image courtesy of Atlas Wearables.
Fig. 4: Machine learning offers an excellent way of implementing compelling services in wearable devices, using personal and sensor data to train algorithms. To take advantage of the technology, however, designers must balance performance with space and power constraints. Atlas Wearables’ Wristband fitness tracker offers a good example of the elements that come into play in the tradeoff process. Image courtesy of Atlas Wearables.Other challenges revolve around compatibility. “Machine learning is normally data-driven,” says Jim Steele, vice president of engineering, intelligent audio, at Knowles Corp. “But the device collecting the data may not be the same as the device that deploys the algorithms. This means the translation of the data between devices needs to be well understood.”
Although issues like design tradeoffs and compatibility arise even in non-machine learning applications, designers will also encounter challenges unique to machine learning implementations. Good examples of these arise when you add sensors to the mix.
Sensor-based systems call for dexterity and high performance. On the one hand, they must be low latency to deal with real-time data streams. At the same time, they must be able to function in less-than-ideal conditions. “Machine learning is only as good as the data collected,” says Steele. “Large amounts of data are not always available [for training], and corner cases are more likely to create user adoption challenges. Therefore, sensor-based machine learning algorithms need to be robust to avoid misclassification caused by these corner cases.
Tools of the Trade
The tools available to design engineers today have come a long way over the past five years. A proliferation of specialized software now provides design teams with the tools needed to deal with many of the challenges encountered when implementing an machine learning-enabled product. This generation of design, modeling and simulation platforms makes machine learning easier to implement across a broad spectrum of scales. In addition, the diversity of artificial intelligence libraries goes a long way toward ensuring that an engineer can find an option to meet the application’s requirements regardless of the preferred language or work environment.
As with other technologies in other times, designers must choose between proprietary or open source tools. Some machine learning-enabled products seem better suited to proprietary tools. “Selecting the ideal tools, modeling, and simulation platforms can be a challenge,” says Steele. “Our engineering team uses a series of proprietary tools for developing, visualizing and incorporating machine learning algorithms into our designs.”
The downside of this approach can be the time and resources required to create these tools. But if the products being enabled by machine learning are specialized enough, the investment proves worthwhile.
Other developers, though, favor more open toolsets. These vary in their level of interoperability and the extent of the feature set.
One example is the Jupyter Notebook, a web-based, open-source, interactive computational environment that allows design engineers to perform numerical simulation, statistical modeling and machine learning. A Jupyter notebook is a JavaScript Object Notation document that contains a list of input/output cells that can contain code, mathematics and plots.
An essential feature—considering the patchwork landscape of tools and work environments—engineers can convert these notebooks into a variety of open standard output formats. Jupyter Notebook is not meant to be an end-to-end solution, but rather one element in a chain of toolsets. “Our team does most of our modeling and testing using Python and Jupyter Notebook running on an AWS EC2 instance [a virtual server in Amazon’s Elastic Compute Cloud],” says Kasparian. “Once we are happy with the results, the algorithm is translated either to low-level C code or in some cases optimized down to Assembly.”
Moving to another level, data science technology company YHat has developed ScienceOps a platform that designers can use to deploy, manage and scale predictive models and decision-making algorithms into production. The platform aims to overcome issues preventing open source statistical tools from interacting with frameworks and languages used to build applications.
YHat has positioned its platform to convert large health datasets into predictive risk models. “YHat helps us accelerate our model development,” says Ash Damle, CEO and founder of Lumiata. “Lumiata is using YHat’s platform to develop our proprietary health-risk algorithms into our AI predictive tool.”
Another resource called CUDA-Convnet, which was developed by Google Code, aims to streamline GPU-accelerated machine learning applications. Written in C++, this machine-learning library aims to exploit NVIDIA’s compute unified device architecture GPU processing technology. In the interest of compatibility, the library supports all the mainstream software, such as Caffe, Torch and Theano.
This is by no means a comprehensive list of the resources available to design teams incorporating machine learning into their development process, but it gives some idea of the breadth of tools at the engineers’ disposal and helps point out some of the issues developers have to acknowledge.
Closing Notes
Machine learning has just begun to evolve, carving out niches in a number of market segments and dramatically reshaping user expectations. As artificial intelligence increasingly goes mainstream, design engineers will have to raise their game.
Paralleling this trend, data science companies are growing the variety of tools at the designers’ disposal. “There is an incredible amount of work and progress happening [in machine learning] all over the world,” says Damle. “There will be more libraries giving easier access to more approaches. We will start to see a greater push for machine learning that can drive engagement within and across industries. We will also see greater understanding and application of man and machine collaboration to make AI relevant and applicable in workflows.”
Although large companies like Google have made great strides in incorporating machine learning into consumer devices, startups have greatly enriched machine learning technology, enabling even greater adoption. “There are some really cool hardware projects going on in this space to optimize running machine learning algorithms,” says Kasparian. Isocline is working on technology that will bring machine learning to more and more embedded and low power devices. And Blazing DB is developing a high-performance GPU database that makes big data SQL lightning fast on GPUs.”
Networking trends also play a role in shaping machine learning. The growing presence of fog computing complements and supports advances in machine learning technology. “Machine learning is mostly trained offline due to reliance on supervised learning and the need for large machines to train the data,” says Steele. “The next five years will most likely see large advances in unsupervised learning and efficient real-time methods to train neural nets that lead to on-device learning. This will allow for more personalized machine learning results.”
More Info
Subscribe to our FREE magazine, FREE email newsletters or both!
Latest News


