MATLAB Moves into the Parallel Domain
Today's increasingly complex problems require multicore machines and clusters and a real need for robust parallel languages.


Latest News
October 1, 2009
By Jos Martin
Today’s engineers are being faced with computational modeling and simulation problems that are growing increasingly larger and it is common for these problems to take weeks or months to solve on a single computer. Recent examples of such large-scale problems include modeling the control systems for the proposed International Linear Collider to be used in high-energy particle physics research, reconstructing protein structure from electron tomography data, and running Monte Carlo simulations of analytic copula models of financials.
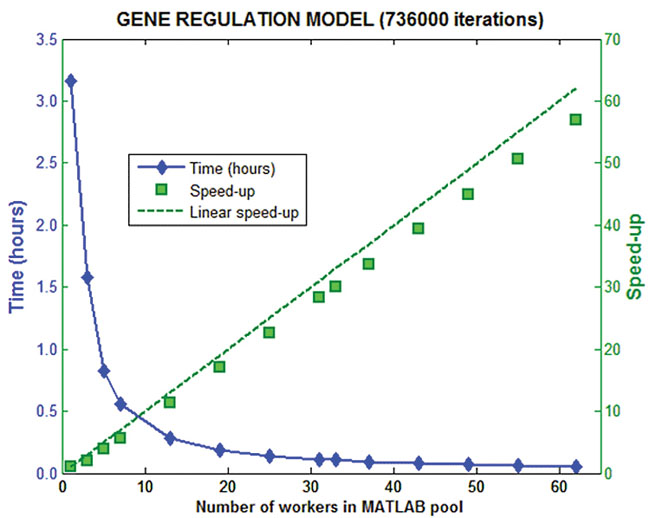 Fig 1: Running a gene regulation model on a cluster using MATLAB Distributed Computing Server. The server enables applications developed using Parallel Computing Toolbox to harness computer clusters for large problems. |
To save time solving these problems, many engineers are turning to both multicore machines and clusters of computers. To use this hardware effectively, they need to use parallel computing technologies.
In order to do this, and until recently, engineers wishing to solve a large-scale problem had two choices: wait until libraries are parallelized or rewrite their code. As we’ll see, there is a problem with current technologies. Instead, we hope to demonstrate how new parallel languages will allow engineers to focus on engineering problems rather than their computer science issues.
Hurry Up and Wait
It might just be possible to wait until the underlying libraries used in your application are rewritten by the vendor to work on parallel hardware. If not, you’re faced with rewriting code using existing parallel techniques such as those provided by OpenMP, Cilk, MPI, or Intel’s Thread Building Blocks (TBB).
For some classes of problems it is reasonable to expect that parallelization of the underlying library code will completely solve the long-term issue and ensure the algorithms will always run well on parallel hardware. An example might be a vendor-supplied computational library. If your libraries have been parallelized, you are fortunate because you have achieved parallelization of your algorithm with no time investment or code changes. In most cases, though, it is likely that the algorithm designer must make code changes to parallelize the algorithm.
Current Parallel Solutions
Parallel techniques like OpenMP, Cilk, MPI, and TBB extend existing languages such as C, C++, and FORTRAN—with a mixture of macro, preprocessor, and library extensions—to enable various forms of parallelism. Except for MPI, these techniques are all variants of a model for which you execute your parallel code on different threads that all have access to the same shared-memory address space. How you express the parallelism in the code varies greatly, but the underlying model is the same.
These programming models are usually considered fairly simple to use and understand. Shared memory access on a single computer is also usually very fast, making it possible to achieve good performance. However, the shared memory assumption of the parallelism model will likely propagate to the design and implementation of the parallel code. This will effectively tie the algorithm to a machine architecture where the time for memory access is low and roughly constant for all cores—namely a single multicore computer.
While this memory access assumption is true for multicore machines today, it is not true for clusters (even when connected over high-speed interconnects such as Infiniband). This makes such techniques unsuitable for scaling algorithms on cluster hardware. And it is looking increasingly likely that the next generation of processors will have an internal architecture more similar to that of a cluster than the multicore computers available today.
The current alternative to shared-memory parallelism is message passing between many processes, known as the message passing interface (MPI) programming model. In this case, the individual parallel parts of the program are considered independent and the only data transfer between the parts is arranged as part of the algorithm.
In general this model tends to minimize the overall data transfer, since the code designer is forced to think explicitly about data movement while writing the code. It also performs much better in a cluster environment for the same reason: The optimized data transfer makes best use of the resources in a cluster. In addition, this approach provides comparable performance to the shared-memory model techniques on a single multicore machine, provided that the message transport layer is of similar performance to shared memory.
However, MPI has often been referred to as “the assembly language for parallel programming” because it is both difficult to program and understand, and mixes algorithm and messaging code together. This leads to complexity in code that is hard to maintain.
Thus, an engineer starting a project today must choose between using a difficult programming model or a simple model that will not work well on a cluster nor likely next-generation hardware. A recent DE article, “Multicore Matters” (July 2009), outlined why parallel software is difficult to write, and discusses the deadlock and race condition problems that can arise in MPI and shared memory code.
What to Expect in Parallel
In this context, newer parallel languages become more than an academic exercise in computer language design. The main goal of any new parallel language is to bridge the divide between performance and programmability; that is, to provide a simple programming model that will work well on multicores and clusters now and in the future.
There are many significant ongoing efforts to develop new languages. Several are funded by the Defense Advanced Research Projects Agency (DARPA) High Productivity Computing Systems (HPCS) program: Chapel from Cray, X10 from IBM, and Fortress from Sun. In addition, Microsoft Research plans to set up groups in its labs to work on parallel language development, and here at The MathWorks we have been moving the MATLAB language into the parallel domain.
A good parallel language must:
• Maintain existing serial programming models
• Provide performance on a range of very different hardware
• Provide a variety of parallel programming models to suit different problems.
To encourage users to adopt a new language and allow simple porting of existing code, the serial code in a new language should look very similar (if not the same) as serial code in an existing language.
There are two parallel problems that are commonly encountered. One, task parallel problems undertake many independent computations at the same time, such as large Monte Carlo simulations. Two, data parallel problems work on large data sets that are spread (partitioned) across the cluster, perhaps treating a data set as a single matrix and manipulating it with linear algebra functions.
Addressing Parallel Problems
Addressing task and data parallel type problems is the first thing that all parallel languages set out to do. In the MATLAB parallel language, distributed arrays and the parfor and spmd (single program multiple data) language constructs solve these problems. Distributed arrays (where the whole array data is spread over the available resources) provide a high-level data parallel model. The parfor construct is a parallel for-loop in which each loop iteration can be executed on any available resource, leading to faster execution of the whole loop. The spmd construct is used to program both with distributed arrays at a low level, and with even lower-level MPI-like constructs. In common with MATLAB, both Chapel and X10 have language constructs that provide these programming models.
Other parallel programming models such as bulk synchronous parallel, task parallel with communication, and map-reduce are needed for some problems, but at significantly lower frequency than the task- and data-parallel models. These other models should be expressible in the language.
A parallel language should also be able to provide protection from deadlocks and race conditions, the bane of current multicore code. MATLAB, X10, and Chapel each include a language subset that is provably free of deadlocks and race conditions; if you program in this subset, you will never encounter these issues.
In addition to this cast-iron guarantee, most parallel languages should be able to detect deadlock conditions in the entire language. This detection ability results from the need for the language to operate effectively on a cluster; to do this it needs a runtime layer (similar in nature to the virtual machine layer in Java) to manage the multi-machine interactions. Automatic deadlock detection can be built into this runtime layer.
Bottom Line for Engineers
These advances leave aspiring parallel programmers in a much better position. They need only express the parallelism of their algorithms in the syntax of the language, with the serial portions of the code being similar to existing code. They may also need to consider some race conditions (i.e., that some parts of the overall algorithm occur in a predefined order).
However, a designer who wants to parallelize an existing algorithm must be willing to invest time to work out how best to express the parallelism inherent in the problem. This task is often subtly different from writing a serial algorithm, and it is here that engineers will need to modify their current approach.
Efficient, robust, and manageable code is produced with this separation of concerns: The language designer provides a clear and easy-to-use set of parallel language constructs and the engineer uses these to express the parallelism specific to their problem. This approach should be the pattern for all scalable algorithmic design on clusters and newer hardware.
More Info:
Cray, Inc.
Jos Martin is the principal architect for parallel computing products at The MathWorks. He holds both an ßMA and D.Phil degrees in Physics from Oxford University in the UK.
Subscribe to our FREE magazine, FREE email newsletters or both!
Latest News
About the Author
DE’s editors contribute news and new product announcements to Digital Engineering.
Press releases may be sent to them via [email protected].


