
Clarifai’s machine learning-based image-recognition tool can learn to recognize particular groups of objects, such as Adidas sneakers. Image courtesy of Clarifai.

Latest News
August 1, 2017
Machine learning (ML) hit public consciousness like a thunderclap, dazzling consumers with technologies like speech recognition and computer vision. Although it may seem like it just emerged, ML has been years in the making. Now the technology promises to dramatically change the way people and machines interact. But there’s a catch.
Look under the hood, and you will find software technology that doesn’t play by many of the old rules that software and design engineers have grown to depend on. As a result, designers implementing ML must approach software development in a new way, using testing practices shaped by the unique nature of its algorithms.
Different Software, Different Testing Practices
Testing traditional software has long been fairly straightforward. Inputs have known outputs. But testing ML algorithms is different.
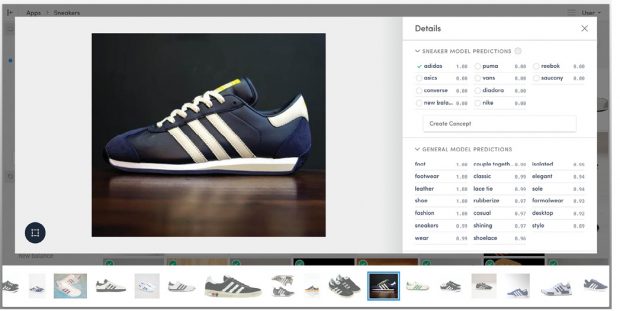 Clarifai’s machine learning-based image-recognition tool can learn to recognize particular groups of objects, such as Adidas sneakers. Image courtesy of Clarifai.
Clarifai’s machine learning-based image-recognition tool can learn to recognize particular groups of objects, such as Adidas sneakers. Image courtesy of Clarifai.To ensure that ML software works properly, the engineer must often deal with “moving targets”—systems whose responses adapt to what they have learned from previous transactions. As a result, they don’t always deliver the same answers. To understand ML testing practices, you need to go back to the basics and understand how the technology works.
Coming to Grips with the Basics
At its core, ML uses computational methods to “learn” directly from data, extracting information unassisted by human intervention. The system’s algorithms accomplish this by finding patterns in data that provide insight and facilitate predictions. These algorithms adaptively improve their performance as the number of learning samples grows. Examples of this technology at work can be seen in the systems used by online companies like Amazon and Netflix, where their machine learning systems provide product or movie recommendations based on user preferences expressed in previous interactions.
Machine learning comes in two flavors: supervised learning and unsupervised learning. This article focuses on supervised machine learning because it is the predominant form found on the market today.
 Using labeled samples, you can train a visual-recognition model to search for specific images. The training samples must be a diverse collection of objects that tells the model what is and is not an appropriate answer. In this case, the visual search is for an Oreo cookie. Image courtesy of Clarifai.
Using labeled samples, you can train a visual-recognition model to search for specific images. The training samples must be a diverse collection of objects that tells the model what is and is not an appropriate answer. In this case, the visual search is for an Oreo cookie. Image courtesy of Clarifai.With supervised learning, the engineer builds a model—an abstraction of the outcome to be predicted—using labeled data, which are examples of the desired answers. For instance, to develop a model that identifies spam, the engineer would use samples of known instances of spam. In this way, a supervised learning algorithm takes a known set of input data and a set of desired responses, and trains a model to generate reasonable predictions.
Supervised learning uses two types of techniques to develop predictive models. Classification techniques predict discrete responses, for example, whether an email is authentic or spam. This technique is used for applications such as speech recognition. On the other hand, engineers use regression techniques to predict continuous conditions, such as temperature changes or commuter traffic volume.
A key component of supervised learning is the neural network. This consists of layered algorithms whose variables can be adjusted through a learning process. Engineers compare the network’s output with known results. When the algorithms achieve the desired accuracy, the developers set the algebraic coefficients and generate production code.
The Development Process
One of the first things the designer has to do to develop a supervised learning algorithm is to determine the type of training examples to be used. For instance, when developing an algorithm seeking to identify spam, the engineer has to decide whether to focus on the sender’s address, subject line or attachments.
After developing a profile of the training samples, the designer must gather the training set. To ensure robust performance, the samples must be representative of the real-world use case. This data set includes inputs and the corresponding outputs.
The next step deals with the feature characteristics. Here, the engineer defines the input feature characteristics of the learned function. The accuracy of the learned function depends greatly on how the input is defined. Typically, the designer converts the input into a feature vector containing characteristics that describe the object. Many machine-learning algorithms use a numerical representation of inputs because it facilitates statistical analysis. In deciding on the number of features to include, the engineer must strike a balance, being sure to include enough information to accurately predict the output.
The designer then determines the structure of the learned function and corresponding learning algorithm. For example, the engineer may decide to use a decision tree.
Upon completing the algorithm’s design, the designer runs the learning algorithm on the training set. Some algorithms require the user to determine control parameters. The engineer may adjust the parameters, optimizing the performance of the validation set.
In the last step, the engineer evaluates the accuracy of the learned function. The performance of the algorithm should be measured on a test set that is different than the training data set.
Finding the Right Algorithm
Choosing the most appropriate type of algorithm for an application is not a straightforward process. There are several to choose from, including linear regression, decision tree, naive Bayes and random forest. Each takes a different approach to learning. Choosing the right one inevitably involves tradeoffs in speed of training, memory usage, predictive accuracy and interpretability (i.e., how easy it is to understand the reasons an algorithm makes its predictions).
Making a selection can turn out to be a trial-and-error process. Fundamentally, however, choosing an algorithm depends on the size and type of data set used, the insights that the designer wants to glean from the data and how the engineer plans to use those insights.
How Much Is too Much?
A key part of the preparation process involves defining the standard acceptable deviation—the amount of error that is acceptable. There is no single rule to guide engineers on how many errors are acceptable. It’s more of a business decision, but there are techniques to help make this call.
“I recommend creating a dependency table to show the tradeoffs between different types of errors,” says Triinu Magi, co-founder and chief technology officer of Neura. “This type of approach enables the business side to determine what is most important to them.”
The Stuff of Models
The model is only as good as the data used to build and train it. An inadequate model translates into inadequate algorithm performance. This means that the selection of the labeled data used to train the model must be complete.
“The challenge is collecting sufficiently large and representative labeled datasets,” says Jin Kim, chief data scientist at Wave Computing.
The designer must be sure to look at all of the relevant data. Making selection decisions based on too narrow of a field of data is a recipe for trouble. “I think the main thing engineers might miss is that they do not represent the entire population of data,” says Magi. “Even when an engineer sees a type of behavior in a small set of data and feels comfortable applying it to the entire set of production data, it still has a huge risk that the data might behave completely different across the entire data set. In this case, instead of expected change, it might cause unexpected system behaviors.”
To ensure that the training data set is complete, the engineer must also be aware of what doesn’t work. “It’s important to understand your failure modes and how severe different kinds of errors are,” says Ryan Compton, head of applied machine learning at Clarifai. “For example, if you’re building an image classifier to spot intruders with a security camera, false negatives are much worse than false positives. When building data sets to train a high-recall classifier such as this, try to collect data with as much variance and diversity as possible. When the goal is high precision, be more specific and cautious that the data you’ve collected is exactly what you want.”
Having the Right Data
Machine learning is basically statistics—predictions that are well trained based on the data that has been collected. But if you look for precision all the time, you are going to be disappointed. It usually does not achieve 100% accuracy.
To test the performance of supervised machine learning algorithms, the designer must understand what he or she wants to achieve by using machine learning and what is expected and accepted behavior. The engineer also needs to understand how machine-learning algorithms can help and what elements to measure to test them. In the testing process, the designer needs feedback that enables him or her to measure the algorithm’s behaviors.
“Establish baselines right off the bat,” says Compton. “Use data as raw as possible, the simplest classifiers available, and record metrics right away. Once the baselines are established, it becomes clear how to track progress.”
Perhaps the most important ingredient is data—the right kind of data. Testing data must adequately represent the general population of the data. At the same time, it should be random. Do not exclude outliers.
“The key challenge is to have correct and true labeled data to validate the models,” says Magi. “For example, for an algorithm to correctly detect that a person is walking, every point in time must be labeled as to whether the person is walking or not. This is very hard to achieve. So a good practice is to set the boundaries—what kind of walking events you want to measure—then try to collect correct labels per these events and measure if the machine learning model manages to detect them.”
To test the algorithm, the engineer must use a data set that is different from the one you used to train it. “Representative labeled data sets need to be separated into training and testing datasets,” says Kim. “You cannot use the same data set to both train and test the machine learning model.”
This practice prevents the algorithm’s intelligence from outsmarting you. “The data we use for training has been used, and the models ‘know’ it well,” says Magi. “The model has learned from that data, so it has a bias to answer the question correctly in such cases. For this reason, it is very important to use new data for testing the model. This approach simulates how the model will behave in a production environment, where every day new unseen data comes in.”
Evaluating Test Results
Design engineers have rules of thumb that they can fall back on when it comes time to weigh the test results of the algorithm’s performance. But decisions made during the preparation phase of the project also help them sort through the many different ways to measure success and find the best approach.
For example, at the beginning of the development process, the engineering and business teams should look at the use case and decide how to weigh factors like accuracy, latency, power consumption, compute budget and real-time analysis.
From these factors, the development team establishes a baseline against which to measure test results. “As far as strictly numeric results are concerned, without a baseline you’ll have no idea if your model is doing well,” says Compton. “For building intuition about what the model is actually doing, investing time into a solid framework that lets engineers visualize results quickly pays generous dividends.”
More Info:
Subscribe to our FREE magazine, FREE email newsletters or both!
Latest News


